Make your IDE reason across your entire system.
Connect your IDE directly to your knowledge map. Every retrieval path, every agent, every indexed source is accessible without leaving your editor.
Everything accessible
Search code, traverse symbols, run agents, create issues, all exposed as MCP tools.
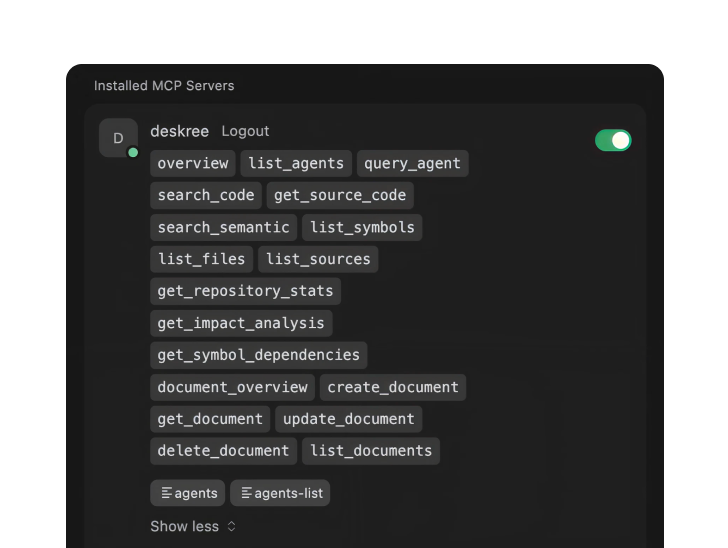
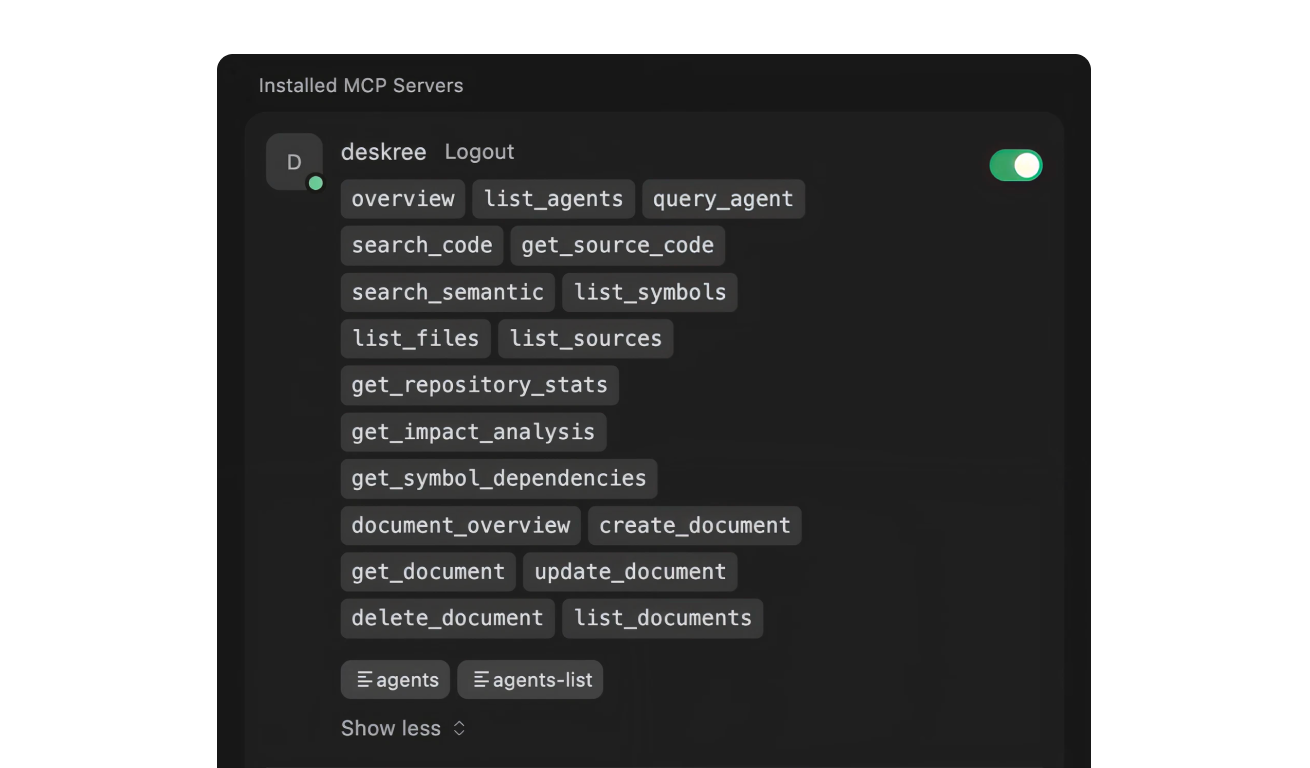
Tetrix exposes its full capabilities as individual MCP tools: code search, semantic search, symbol graph traversal, document retrieval, agent queries, and issue creation across agents. Access all of them from inside your IDE. No tab-switching, no copy-pasting between tools.
See how ingestion worksPre-mapped knowledge
Your IDE reads from pre-mapped knowledge. Not raw files.
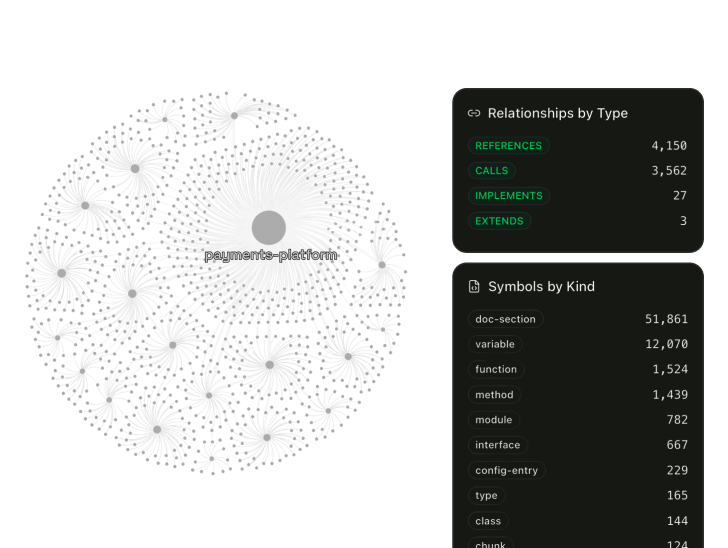
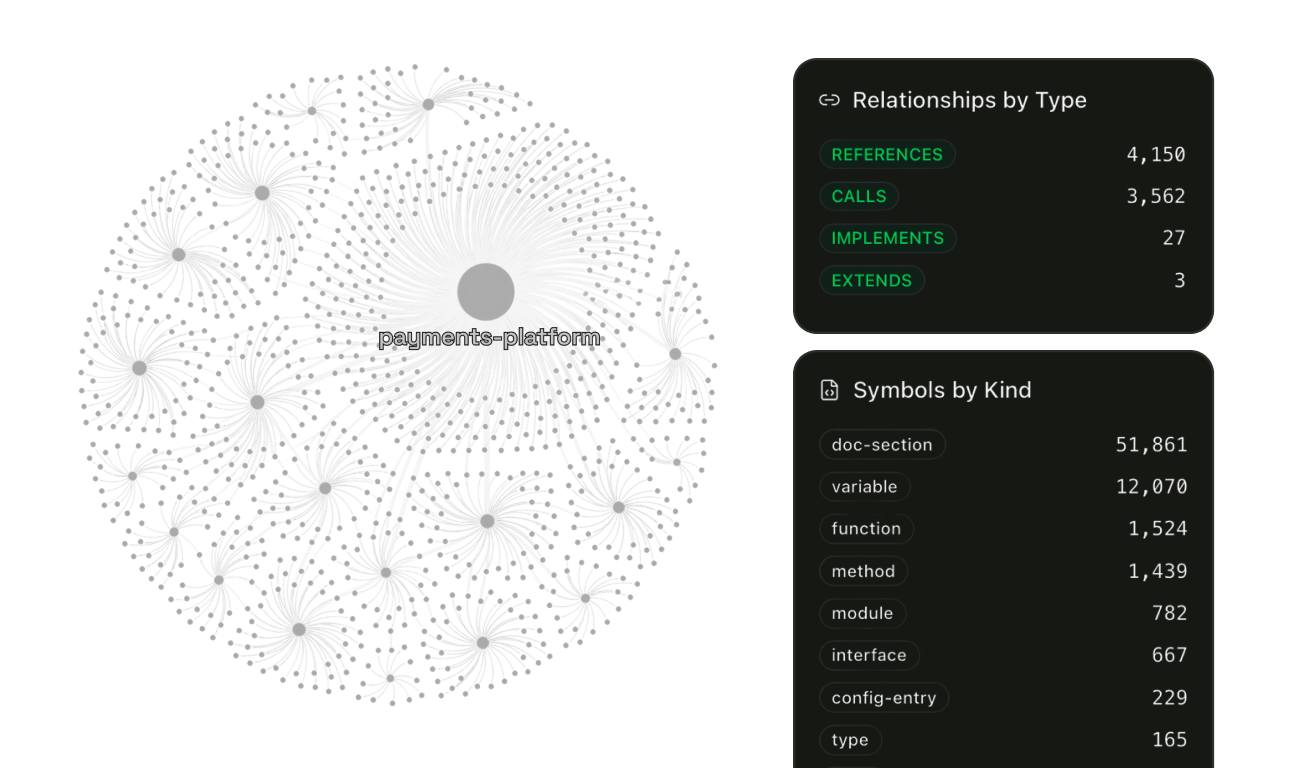
Your IDE gets structured knowledge: symbol relationships pre-computed at index time, cross-repository dependency chains already resolved, architecture standards and engineering docs indexed alongside code. Your LLM isn't reconstructing your system from whatever files are in the buffer. It's querying structure that already exists.
Millisecond retrieval
Fewer reads. Structured lookup. Millisecond retrieval at any codebase size.
Every IDE without a knowledge graph discovers context the same way. It reads files one at a time. Bigger codebase, longer reads, longer wait. Tetrix answers cross-repository questions through structured MCP calls against a pre-computed graph. Each call resolves in milliseconds. 10K indexed symbols filtered in 11ms. 100K in 13.7ms. Relationships are computed once at index time, not rediscovered on every query.
Reduced token consumption
Less context discovery. Lower cost per query.
In standard IDE integrations, every query burns tokens reconstructing context. Tetrix has already done that work at index time. Your LLM skips discovery entirely and reasons directly over structured knowledge. Fewer tokens spent on context discovery. Higher accuracy per token spent.
See how the graph is built